1. 什么是 Active Record 查询接口?
如果您习惯于使用原始 SQL 查找数据库记录,那么您通常会发现 Rails 中有更好的方法来执行相同的操作。Active Record 在大多数情况下将您与使用 SQL 的需要隔离开来。
Active Record 将为您在数据库上执行查询,并与大多数数据库系统兼容,包括 MySQL、MariaDB、PostgreSQL 和 SQLite。无论您使用哪种数据库系统,Active Record 方法格式都将始终相同。
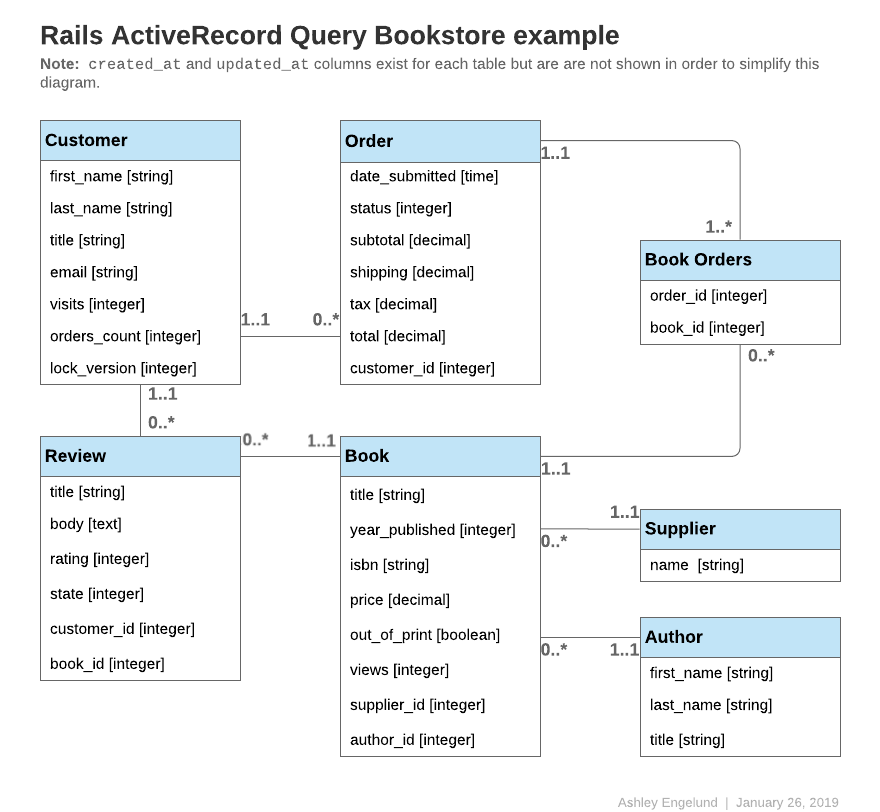
本指南中的代码示例将引用以下一个或多个模型
除非另有说明,否则以下所有模型都使用 id 作为主键。
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
class Book < ApplicationRecord
belongs_to :supplier
belongs_to :author
has_many :reviews
has_and_belongs_to_many :orders, join_table: "books_orders"
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
scope :out_of_print_and_expensive, -> { out_of_print.where("price > 500") }
scope :costs_more_than, ->(amount) { where("price > ?", amount) }
end
class Customer < ApplicationRecord
has_many :orders
has_many :reviews
end
class Order < ApplicationRecord
belongs_to :customer
has_and_belongs_to_many :books, join_table: "books_orders"
enum :status, [:shipped, :being_packed, :complete, :cancelled]
scope :created_before, ->(time) { where(created_at: ...time) }
end
class Review < ApplicationRecord
belongs_to :customer
belongs_to :book
enum :state, [:not_reviewed, :published, :hidden]
end
class Supplier < ApplicationRecord
has_many :books
has_many :authors, through: :books
end
2. 从数据库检索对象
为了从数据库检索对象,Active Record 提供了几个查找方法。每个查找方法都允许您向其传递参数,以便在数据库上执行某些查询,而无需编写原始 SQL。
这些方法是
annotatefindcreate_withdistincteager_loadextendingextract_associatedfromgrouphavingincludesjoinsleft_outer_joinslimitlocknoneoffsetoptimizer_hintsorderpreloadreadonlyreferencesreorderreselectregroupreverse_orderselectwhere
返回集合的查找方法(例如 where 和 group)返回 ActiveRecord::Relation 的实例。查找单个实体的方法(例如 find 和 first)返回模型的单个实例。
Model.find(options) 的主要操作可以概括为
- 将提供的选项转换为等效的 SQL 查询。
- 执行 SQL 查询并从数据库检索相应结果。
- 为每个结果行实例化相应模型的等效 Ruby 对象。
- 如果有,运行
after_find,然后运行after_initialize回调。
2.1. 检索单个对象
Active Record 提供了几种不同的检索单个对象的方法。
2.1.1. find
使用 find 方法,您可以检索与指定主键对应且与任何提供的选项匹配的对象。例如
# Find the customer with primary key (id) 10.
irb> customer = Customer.find(10)
=> #<Customer id: 10, first_name: "Ryan">
上述内容的 SQL 等效项是
SELECT * FROM customers WHERE (customers.id = 10) LIMIT 1
如果未找到匹配记录,find 方法将引发 ActiveRecord::RecordNotFound 异常。
您也可以使用此方法查询多个对象。调用 find 方法并传入一个主键数组。返回值将是一个数组,其中包含提供的主键的所有匹配记录。例如
# Find the customers with primary keys 1 and 10.
irb> customers = Customer.find([1, 10]) # OR Customer.find(1, 10)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 10, first_name: "Ryan">]
上述内容的 SQL 等效项是
SELECT * FROM customers WHERE (customers.id IN (1,10))
除非为**所有**提供的主键找到匹配记录,否则 find 方法将引发 ActiveRecord::RecordNotFound 异常。
如果您的表使用复合主键,您需要传入一个数组来查找单个项。例如,如果客户被定义为 [:store_id, :id] 作为主键
# Find the customer with store_id 3 and id 17
irb> customers = Customer.find([3, 17])
=> #<Customer store_id: 3, id: 17, first_name: "Magda">
上述内容的 SQL 等效项是
SELECT * FROM customers WHERE store_id = 3 AND id = 17
要查找具有复合 ID 的多个客户,您可以传入一个数组的数组
# Find the customers with primary keys [1, 8] and [7, 15].
irb> customers = Customer.find([[1, 8], [7, 15]]) # OR Customer.find([1, 8], [7, 15])
=> [#<Customer store_id: 1, id: 8, first_name: "Pat">, #<Customer store_id: 7, id: 15, first_name: "Chris">]
上述内容的 SQL 等效项是
SELECT * FROM customers WHERE (store_id = 1 AND id = 8 OR store_id = 7 AND id = 15)
2.1.2. take
take 方法检索记录,不带任何隐式排序。例如
irb> customer = Customer.take
=> #<Customer id: 1, first_name: "Lifo">
上述内容的 SQL 等效项是
SELECT * FROM customers LIMIT 1
如果未找到记录,take 方法返回 nil,并且不会引发异常。
您可以向 take 方法传入一个数字参数,以返回最多该数量的结果。例如
irb> customers = Customer.take(2)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 220, first_name: "Sara">]
上述内容的 SQL 等效项是
SELECT * FROM customers LIMIT 2
take! 方法的行为与 take 完全相同,不同之处在于如果未找到匹配记录,它将引发 ActiveRecord::RecordNotFound。
检索到的记录可能因数据库引擎而异。
2.1.3. first
first 方法按主键查找第一条记录(默认)。例如
irb> customer = Customer.first
=> #<Customer id: 1, first_name: "Lifo">
上述内容的 SQL 等效项是
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 1
如果未找到匹配记录,first 方法返回 nil,并且不会引发异常。
如果您的 默认作用域 包含一个排序方法,first 将根据此排序返回第一条记录。
您可以向 first 方法传入一个数字参数,以返回最多该数量的结果。例如
irb> customers = Customer.first(3)
=> [#<Customer id: 1, first_name: "Lifo">, #<Customer id: 2, first_name: "Fifo">, #<Customer id: 3, first_name: "Filo">]
上述内容的 SQL 等效项是
SELECT * FROM customers ORDER BY customers.id ASC LIMIT 3
具有复合主键的模型将使用完整的复合主键进行排序。例如,如果客户被定义为 [:store_id, :id] 作为主键
irb> customer = Customer.first
=> #<Customer id: 2, store_id: 1, first_name: "Lifo">
上述内容的 SQL 等效项是
SELECT * FROM customers ORDER BY customers.store_id ASC, customers.id ASC LIMIT 1
对于使用 order 排序的集合,first 将返回按 order 指定属性排序的第一条记录。
irb> customer = Customer.order(:first_name).first
=> #<Customer id: 2, first_name: "Fifo">
上述内容的 SQL 等效项是
SELECT * FROM customers ORDER BY customers.first_name ASC LIMIT 1
first! 方法的行为与 first 完全相同,不同之处在于如果未找到匹配记录,它将引发 ActiveRecord::RecordNotFound。
2.1.4. last
last 方法按主键查找最后一条记录(默认)。例如
irb> customer = Customer.last
=> #<Customer id: 221, first_name: "Russel">
上述内容的 SQL 等效项是
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 1
如果未找到匹配记录,last 方法返回 nil,并且不会引发异常。
具有复合主键的模型将使用完整的复合主键进行排序。例如,如果客户被定义为 [:store_id, :id] 作为主键
irb> customer = Customer.last
=> #<Customer id: 221, store_id: 1, first_name: "Lifo">
上述内容的 SQL 等效项是
SELECT * FROM customers ORDER BY customers.store_id DESC, customers.id DESC LIMIT 1
如果您的 默认作用域 包含一个排序方法,last 将根据此排序返回最后一条记录。
您可以向 last 方法传入一个数字参数,以返回最多该数量的结果。例如
irb> customers = Customer.last(3)
=> [#<Customer id: 219, first_name: "James">, #<Customer id: 220, first_name: "Sara">, #<Customer id: 221, first_name: "Russel">]
上述内容的 SQL 等效项是
SELECT * FROM customers ORDER BY customers.id DESC LIMIT 3
对于使用 order 排序的集合,last 将返回按 order 指定属性排序的最后一条记录。
irb> customer = Customer.order(:first_name).last
=> #<Customer id: 220, first_name: "Sara">
上述内容的 SQL 等效项是
SELECT * FROM customers ORDER BY customers.first_name DESC LIMIT 1
last! 方法的行为与 last 完全相同,不同之处在于如果未找到匹配记录,它将引发 ActiveRecord::RecordNotFound。
2.1.5. find_by
find_by 方法查找匹配某些条件的第一条记录。例如
irb> Customer.find_by first_name: 'Lifo'
=> #<Customer id: 1, first_name: "Lifo">
irb> Customer.find_by first_name: 'Jon'
=> nil
它等效于编写
Customer.where(first_name: "Lifo").take
上述内容的 SQL 等效项是
SELECT * FROM customers WHERE (customers.first_name = 'Lifo') LIMIT 1
请注意,上述 SQL 中没有 ORDER BY。如果您的 find_by 条件可以匹配多条记录,您应该 应用排序 以保证确定性结果。
find_by! 方法的行为与 find_by 完全相同,不同之处在于如果未找到匹配记录,它将引发 ActiveRecord::RecordNotFound。例如
irb> Customer.find_by! first_name: 'does not exist'
ActiveRecord::RecordNotFound
这等效于编写
Customer.where(first_name: "does not exist").take!
2.1.5.1. 带有 :id 的条件
在 find_by 和 where 等方法上指定条件时,使用 id 将匹配模型上的 :id 属性。这与 find 不同,其中传入的 ID 应该是一个主键值。
当在 :id 不是主键的模型(例如复合主键模型)上使用 find_by(id:) 时,请务必小心。例如,如果客户被定义为 [:store_id, :id] 作为主键
irb> customer = Customer.last
=> #<Customer id: 10, store_id: 5, first_name: "Joe">
irb> Customer.find_by(id: customer.id) # Customer.find_by(id: [5, 10])
=> #<Customer id: 5, store_id: 3, first_name: "Bob">
这里,我们可能打算搜索具有复合主键 [5, 10] 的单个记录,但 Active Record 将搜索 :id 列为 5 或 10 的记录,并可能返回错误的记录。
id_value 方法可用于获取记录的 :id 列的值,以便在 find_by 和 where 等查找方法中使用。请参阅下面的示例
irb> customer = Customer.last
=> #<Customer id: 10, store_id: 5, first_name: "Joe">
irb> Customer.find_by(id: customer.id_value) # Customer.find_by(id: 10)
=> #<Customer id: 10, store_id: 5, first_name: "Joe">
2.2. 批量检索多个对象
我们经常需要遍历大量记录,例如当我们向大量客户发送新闻稿,或者当我们导出数据时。
这可能看起来很简单
# This may consume too much memory if the table is big.
Customer.all.each do |customer|
NewsMailer.weekly(customer).deliver_now
end
但随着表大小的增加,这种方法变得越来越不实用,因为 Customer.all.each 指示 Active Record 一次性获取**整个表**,为每一行构建一个模型对象,然后将整个模型对象数组保留在内存中。实际上,如果记录数量很大,整个集合可能会超出可用内存量。
Rails 提供了两种方法来解决这个问题,通过将记录分成内存友好的批次进行处理。第一种方法 find_each 检索一批记录,然后将**每条**记录作为模型单独提供给块。第二种方法 find_in_batches 检索一批记录,然后将**整个批次**作为模型数组提供给块。
find_each 和 find_in_batches 方法旨在用于批量处理无法一次性全部放入内存的大量记录。如果您只需要遍历一千条记录,则常规查找方法是首选。
2.2.1. find_each
find_each 方法批量检索记录,然后将**每条**记录提供给块。在以下示例中,find_each 以 1000 条记录的批次检索客户,并逐个将它们提供给块
Customer.find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
此过程重复进行,根据需要获取更多批次,直到所有记录都已处理完毕。
find_each 作用于模型类(如上所示),也作用于关系
Customer.where(weekly_subscriber: true).find_each do |customer|
NewsMailer.weekly(customer).deliver_now
end
只要它们没有排序,因为该方法需要在内部强制排序以进行迭代。
如果接收者中存在排序,则行为取决于标志 config.active_record.error_on_ignored_order。如果为 true,则会引发 ArgumentError,否则排序将被忽略并发出警告(这是默认行为)。这可以通过选项 :error_on_ignore(如下所述)覆盖。
2.2.1.1. find_each 的选项
:batch_size
:batch_size 选项允许您指定在每个批次中检索的记录数,然后单独传递给块。例如,以 5000 条记录的批次检索记录
Customer.find_each(batch_size: 5000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:start
默认情况下,记录按主键升序获取。当最低 ID 不是您需要的 ID 时,:start 选项允许您配置序列的第一个 ID。这在您想要恢复中断的批处理过程时很有用,前提是您已将最后处理的 ID 保存为检查点。
例如,仅向主键从 2000 开始的客户发送新闻稿
Customer.find_each(start: 2000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
:finish
与 :start 选项类似,:finish 允许您配置序列的最后一个 ID,当最高 ID 不是您需要的 ID 时。这在您想要使用基于 :start 和 :finish 的记录子集运行批处理过程时很有用。
例如,仅向主键从 2000 到 10000 的客户发送新闻稿
Customer.find_each(start: 2000, finish: 10000) do |customer|
NewsMailer.weekly(customer).deliver_now
end
另一个例子是,如果您希望多个工作线程处理相同的处理队列。您可以让每个工作线程通过在每个工作线程上设置适当的 :start 和 :finish 选项来处理 10000 条记录。
:error_on_ignore
覆盖应用程序配置,以指定当关系中存在顺序时是否应引发错误。
:order
指定主键顺序(可以是 :asc 或 :desc)。默认为 :asc。
Customer.find_each(order: :desc) do |customer|
NewsMailer.weekly(customer).deliver_now
end
2.2.2. find_in_batches
find_in_batches 方法与 find_each 类似,因为它们都检索批次记录。不同之处在于 find_in_batches 以模型数组的形式将**批次**提供给块,而不是单独提供。以下示例将向提供的块提供每次最多 1000 个客户的数组,最后一个块包含所有剩余的客户
# Give add_customers an array of 1000 customers at a time.
Customer.find_in_batches do |customers|
export.add_customers(customers)
end
find_in_batches 作用于模型类(如上所示),也作用于关系
# Give add_customers an array of 1000 recently active customers at a time.
Customer.recently_active.find_in_batches do |customers|
export.add_customers(customers)
end
只要它们没有排序,因为该方法需要在内部强制排序以进行迭代。
2.2.2.1. find_in_batches 的选项
find_in_batches 方法接受与 find_each 相同的选项
:batch_size
与 find_each 类似,batch_size 确定每个组中将检索多少条记录。例如,检索 2500 条记录的批次可以指定为
Customer.find_in_batches(batch_size: 2500) do |customers|
export.add_customers(customers)
end
:start
start 选项允许指定将从中选择记录的起始 ID。如前所述,默认情况下,记录按主键升序获取。例如,要以 2500 条记录的批次检索从 ID 5000 开始的客户,可以使用以下代码
Customer.find_in_batches(batch_size: 2500, start: 5000) do |customers|
export.add_customers(customers)
end
:finish
finish 选项允许指定要检索的记录的结束 ID。下面的代码显示了批量检索客户的情况,最多到 ID 为 7000 的客户
Customer.find_in_batches(finish: 7000) do |customers|
export.add_customers(customers)
end
:error_on_ignore
error_on_ignore 选项会覆盖应用程序配置,以指定当关系中存在特定顺序时是否应引发错误。
3. 条件
where 方法允许您指定条件以限制返回的记录,代表 SQL 语句的 WHERE 部分。条件可以指定为字符串、数组或哈希。
3.1. 纯字符串条件
如果您想在查找中添加条件,只需在其中指定即可,就像 Book.where("title = 'Introduction to Algorithms'")。这将查找所有 title 字段值为 'Introduction to Algorithms' 的书籍。
将您自己的条件构建为纯字符串可能会使您容易受到 SQL 注入漏洞的攻击。例如,Book.where("title LIKE '%#{params[:title]}%'") 不安全。请参阅下一节,了解使用数组处理条件的优选方法。
3.2. 数组条件
那么,如果标题可能有所不同,例如作为某个地方的参数呢?查找将采用以下形式
Book.where("title = ?", params[:title])
Active Record 将第一个参数作为条件字符串,任何附加参数将替换其中的问号 (?)。
如果您想指定多个条件
Book.where("title = ? AND out_of_print = ?", params[:title], false)
在此示例中,第一个问号将替换为 params[:title] 中的值,第二个问号将替换为 false 的 SQL 表示,这取决于适配器。
此代码高度优于
Book.where("title = ?", params[:title])
此代码
Book.where("title = #{params[:title]}")
因为参数安全。将变量直接放入条件字符串将把变量**原样**传递给数据库。这意味着它将是一个未经转义的变量,直接来自可能具有恶意意图的用户。如果您这样做,您将使整个数据库面临风险,因为一旦用户发现他们可以利用您的数据库,他们就可以对它做任何事情。永远不要将您的参数直接放入条件字符串中。
有关 SQL 注入危险的更多信息,请参阅 Ruby on Rails 安全指南。
3.2.1. 占位符条件
与参数的 (?) 替换样式类似,您还可以在条件字符串中指定键以及相应的键/值哈希
Book.where("created_at >= :start_date AND created_at <= :end_date",
{ start_date: params[:start_date], end_date: params[:end_date] })
如果您有大量可变条件,这将使可读性更清晰。
3.2.2. 使用 LIKE 的条件
尽管条件参数会自动转义以防止 SQL 注入,但 SQL LIKE 通配符(即 % 和 _)**不会**转义。如果参数中使用未经清理的值,这可能会导致意外行为。例如
Book.where("title LIKE ?", params[:title] + "%")
在上述代码中,目的是匹配以用户指定字符串开头的标题。但是,params[:title] 中的任何 % 或 _ 都将被视为通配符,导致令人惊讶的查询结果。在某些情况下,这还可能阻止数据库使用预期的索引,从而导致查询速度大大变慢。
为了避免这些问题,请使用 sanitize_sql_like 来转义参数相关部分的通配符
Book.where("title LIKE ?",
Book.sanitize_sql_like(params[:title]) + "%")
3.3. 哈希条件
Active Record 还允许您传入哈希条件,这可以提高条件语法的可读性。使用哈希条件,您传入一个哈希,其中包含要限定的字段的键和要限定它们的值
哈希条件只能进行相等性、范围和子集检查。
3.3.1. 相等条件
Book.where(out_of_print: true)
这将生成如下 SQL
SELECT * FROM books WHERE (books.out_of_print = 1)
字段名也可以是字符串
Book.where("out_of_print" => true)
在 belongs_to 关系的情况下,如果使用 Active Record 对象作为值,则可以使用关联键来指定模型。此方法也适用于多态关系。
author = Author.first
Book.where(author: author)
Author.joins(:books).where(books: { author: author })
哈希条件也可以以元组式语法指定,其中键是列的数组,值是元组的数组
Book.where([:author_id, :id] => [[15, 1], [15, 2]])
此语法对于查询表使用复合主键的关系非常有用
class Book < ApplicationRecord
self.primary_key = [:author_id, :id]
end
Book.where(Book.primary_key => [[2, 1], [3, 1]])
3.3.2. 范围条件
Book.where(created_at: (Time.now.midnight - 1.day)..Time.now.midnight)
这将使用 BETWEEN SQL 语句查找昨天创建的所有书籍
SELECT * FROM books WHERE (books.created_at BETWEEN '2008-12-21 00:00:00' AND '2008-12-22 00:00:00')
这展示了 数组条件 中的示例的更短语法
支持无始和无终范围,可用于构建小于/大于条件。
Book.where(created_at: (Time.now.midnight - 1.day)..)
这将生成如下 SQL
SELECT * FROM books WHERE books.created_at >= '2008-12-21 00:00:00'
3.3.3. 子集条件
如果您想使用 IN 表达式查找记录,可以将数组传递给条件哈希
Customer.where(orders_count: [1, 3, 5])
此代码将生成如下 SQL
SELECT * FROM customers WHERE (customers.orders_count IN (1,3,5))
3.4. NOT 条件
NOT SQL 查询可以通过 where.not 构建
Customer.where.not(orders_count: [1, 3, 5])
换句话说,可以通过调用不带参数的 where,然后立即链式调用 not 并传入 where 条件来生成此查询。这将生成如下 SQL
SELECT * FROM customers WHERE (customers.orders_count NOT IN (1,3,5))
如果查询在可空列上具有非空值的哈希条件,则不会返回在该可空列上具有 nil 值的记录。例如
Customer.create!(nullable_country: nil)
Customer.where.not(nullable_country: "UK")
# => []
# But
Customer.create!(nullable_country: "UK")
Customer.where.not(nullable_country: nil)
# => [#<Customer id: 2, nullable_country: "UK">]
3.5. OR 条件
两个关系之间的 OR 条件可以通过在第一个关系上调用 or 并将第二个关系作为参数传入来构建。
Customer.where(last_name: "Smith").or(Customer.where(orders_count: [1, 3, 5]))
SELECT * FROM customers WHERE (customers.last_name = 'Smith' OR customers.orders_count IN (1,3,5))
3.6. AND 条件
AND 条件可以通过链式 where 条件构建。
Customer.where(last_name: "Smith").where(orders_count: [1, 3, 5])
SELECT * FROM customers WHERE customers.last_name = 'Smith' AND customers.orders_count IN (1,3,5)
关系之间逻辑交集的 AND 条件可以通过在第一个关系上调用 and 并将第二个关系作为参数传入来构建。
Customer.where(id: [1, 2]).and(Customer.where(id: [2, 3]))
SELECT * FROM customers WHERE (customers.id IN (1, 2) AND customers.id IN (2, 3))
4. 排序
要从数据库中以特定顺序检索记录,可以使用 order 方法。
例如,如果您正在获取一组记录并希望按表中 created_at 字段的升序排序
Book.order(:created_at)
# OR
Book.order("created_at")
您也可以指定 ASC 或 DESC
Book.order(created_at: :desc)
# OR
Book.order(created_at: :asc)
# OR
Book.order("created_at DESC")
# OR
Book.order("created_at ASC")
或按多个字段排序
Book.order(title: :asc, created_at: :desc)
# OR
Book.order(:title, created_at: :desc)
# OR
Book.order("title ASC, created_at DESC")
# OR
Book.order("title ASC", "created_at DESC")
如果您想多次调用 order,后续的顺序将附加到第一个顺序之后
irb> Book.order("title ASC").order("created_at DESC")
SELECT * FROM books ORDER BY title ASC, created_at DESC
您也可以从连接的表进行排序
Book.includes(:author).order(books: { print_year: :desc }, authors: { name: :asc })
# OR
Book.includes(:author).order("books.print_year desc", "authors.name asc")
在大多数数据库系统中,使用 select、pluck 和 ids 等方法从结果集中使用 distinct 选择字段时,order 方法将引发 ActiveRecord::StatementInvalid 异常,除非 order 子句中使用的字段包含在选择列表中。请参阅下一节,了解从结果集中选择字段。
5. 选择特定字段
默认情况下,Model.find 使用 select * 从结果集中选择所有字段。
要仅从结果集中选择字段的子集,可以通过 select 方法指定子集。
例如,要仅选择 isbn 和 out_of_print 列
Book.select(:isbn, :out_of_print)
# OR
Book.select("isbn, out_of_print")
此查找调用使用的 SQL 查询将类似于
SELECT isbn, out_of_print FROM books
请注意,这还意味着您正在使用仅选择了的字段初始化模型对象。如果您尝试访问未在初始化记录中的字段,您将收到
ActiveModel::MissingAttributeError: missing attribute '<attribute>' for Book
其中 <attribute> 是您请求的属性。id 方法不会引发 ActiveRecord::MissingAttributeError,因此在使用关联时请务必小心,因为它们需要 id 方法才能正常运行。
如果您只想根据某个字段中的唯一值获取一条记录,可以使用 distinct
Customer.select(:last_name).distinct
这将生成如下 SQL
SELECT DISTINCT last_name FROM customers
您还可以删除唯一性约束
# Returns unique last_names
query = Customer.select(:last_name).distinct
# Returns all last_names, even if there are duplicates
query.distinct(false)
6. 限制和偏移量
要将 LIMIT 应用于 Model.find 触发的 SQL,您可以使用关系上的 limit 和 offset 方法指定 LIMIT。
您可以使用 limit 指定要检索的记录数,并使用 offset 指定在开始返回记录之前跳过的记录数。例如
Customer.limit(5)
将最多返回 5 个客户,并且由于未指定偏移量,它将返回表中的前 5 个客户。它执行的 SQL 如下所示
SELECT * FROM customers LIMIT 5
加上 offset
Customer.limit(5).offset(30)
将改为返回最多 5 个客户,从第 31 个开始。SQL 如下所示
SELECT * FROM customers LIMIT 5 OFFSET 30
7. 分组
要将 GROUP BY 子句应用于查找器触发的 SQL,可以使用 group 方法。
例如,如果您想查找订单创建日期的集合
Order.select("created_at").group("created_at")
这将为您提供数据库中每个有订单的日期的一个 Order 对象。
将执行的 SQL 将类似于
SELECT created_at
FROM orders
GROUP BY created_at
7.1. 分组项总计
要在单个查询中获取分组项的总计,请在 group 之后调用 count。
irb> Order.group(:status).count
=> {"being_packed"=>7, "shipped"=>12}
将执行的 SQL 将类似于
SELECT COUNT (*) AS count_all, status AS status
FROM orders
GROUP BY status
7.2. HAVING 条件
SQL 使用 HAVING 子句来指定 GROUP BY 字段的条件。您可以通过将 having 方法添加到查找中,将 HAVING 子句添加到 Model.find 触发的 SQL 中。
例如
Order.select("created_at as ordered_date, sum(total) as total_price").
group("created_at").having("sum(total) > ?", 200)
将执行的 SQL 将类似于
SELECT created_at as ordered_date, sum(total) as total_price
FROM orders
GROUP BY created_at
HAVING sum(total) > 200
这将返回每个订单对象的日期和总价,按订购日期分组,并且总价超过 $200。
您将像这样访问返回的每个订单对象的 total_price
big_orders = Order.select("created_at, sum(total) as total_price")
.group("created_at")
.having("sum(total) > ?", 200)
big_orders[0].total_price
# Returns the total price for the first Order object
8. 覆盖条件
8.1. unscope
您可以使用 unscope 方法指定要删除的某些条件。例如
Book.where("id > 100").limit(20).order("id desc").unscope(:order)
将执行的 SQL
SELECT * FROM books WHERE id > 100 LIMIT 20
-- Original query without `unscope`
SELECT * FROM books WHERE id > 100 ORDER BY id desc LIMIT 20
您还可以取消特定 where 子句的作用域。例如,这将从 where 子句中删除 id 条件
Book.where(id: 10, out_of_print: false).unscope(where: :id)
# SELECT books.* FROM books WHERE out_of_print = 0
已使用 unscope 的关系将影响与之合并的任何关系
Book.order("id desc").merge(Book.unscope(:order))
# SELECT books.* FROM books
8.2. only
您还可以使用 only 方法覆盖条件。例如
Book.where("id > 10").limit(20).order("id desc").only(:order, :where)
将执行的 SQL
SELECT * FROM books WHERE id > 10 ORDER BY id DESC
-- Original query without `only`
SELECT * FROM books WHERE id > 10 ORDER BY id DESC LIMIT 20
8.3. reselect
reselect 方法覆盖现有的 select 语句。例如
Book.select(:title, :isbn).reselect(:created_at)
将执行的 SQL
SELECT books.created_at FROM books
将其与未使用 reselect 子句的情况进行比较
Book.select(:title, :isbn).select(:created_at)
将执行的 SQL 将是
SELECT books.title, books.isbn, books.created_at FROM books
8.4. reorder
reorder 方法覆盖默认作用域顺序。例如,如果类定义包含此
class Author < ApplicationRecord
has_many :books, -> { order(year_published: :desc) }
end
并且您执行此操作
Author.find(10).books
将执行的 SQL
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published DESC
您可以使用 reorder 子句来指定不同的书籍排序方式
Author.find(10).books.reorder("year_published ASC")
将执行的 SQL
SELECT * FROM authors WHERE id = 10 LIMIT 1
SELECT * FROM books WHERE author_id = 10 ORDER BY year_published ASC
8.5. reverse_order
reverse_order 方法反转指定的排序子句。
Book.where("author_id > 10").order(:year_published).reverse_order
将执行的 SQL
SELECT * FROM books WHERE author_id > 10 ORDER BY year_published DESC
如果在查询中未指定排序子句,reverse_order 将按主键逆序排序。
Book.where("author_id > 10").reverse_order
将执行的 SQL
SELECT * FROM books WHERE author_id > 10 ORDER BY books.id DESC
reverse_order 方法不接受**任何**参数。
8.6. rewhere
rewhere 方法覆盖现有命名 where 条件。例如
Book.where(out_of_print: true).rewhere(out_of_print: false)
将执行的 SQL
SELECT * FROM books WHERE out_of_print = 0
如果未使用 rewhere 子句,则 where 子句通过 AND 组合在一起
Book.where(out_of_print: true).where(out_of_print: false)
将执行的 SQL 将是
SELECT * FROM books WHERE out_of_print = 1 AND out_of_print = 0
8.7. regroup
regroup 方法覆盖现有命名 group 条件。例如
Book.group(:author).regroup(:id)
将执行的 SQL
SELECT * FROM books GROUP BY id
如果未使用 regroup 子句,则 group 子句会组合在一起
Book.group(:author).group(:id)
将执行的 SQL 将是
SELECT * FROM books GROUP BY author, id
9. 空关系
none 方法返回一个没有记录的可链式关系。任何后续链式到返回关系上的条件将继续生成空关系。这在您需要对可能返回零结果的方法或作用域进行可链式响应的场景中很有用。
Book.none # returns an empty Relation and fires no queries.
# The highlighted_reviews method below is expected to always return a Relation.
Book.first.highlighted_reviews.average(:rating)
# => Returns average rating of a book
class Book
# Returns reviews if there are at least 5,
# else consider this as non-reviewed book
def highlighted_reviews
if reviews.count >= 5
reviews
else
Review.none # Does not meet minimum threshold yet
end
end
end
10. 只读对象
Active Record 在关系上提供了 readonly 方法,以明确禁止修改任何返回的对象。任何尝试更改只读记录的操作都将失败,并引发 ActiveRecord::ReadOnlyRecord 异常。
customer = Customer.readonly.first
customer.visits += 1
customer.save # Raises an ActiveRecord::ReadOnlyRecord
由于 customer 被明确设置为只读对象,因此当调用 customer.save 并更新 visits 值时,上述代码将引发 ActiveRecord::ReadOnlyRecord 异常。
11. 锁定记录以进行更新
锁定有助于在更新数据库中的记录时防止竞态条件并确保原子更新。
Active Record 提供了两种锁定机制
- 乐观锁
- 悲观锁
11.1. 乐观锁
乐观锁允许多个用户访问同一记录进行编辑,并假定数据冲突最小。它通过检查自记录打开以来是否有其他进程对记录进行了更改来实现这一点。如果发生这种情况,则会抛出 ActiveRecord::StaleObjectError 异常,并且更新将被忽略。
乐观锁列
为了使用乐观锁,表需要有一个名为 lock_version 的整数类型列。每次更新记录时,Active Record 都会增加 lock_version 列。如果更新请求中 lock_version 字段的值低于数据库中 lock_version 列的当前值,则更新请求将失败并出现 ActiveRecord::StaleObjectError。
例如
c1 = Customer.find(1)
c2 = Customer.find(1)
c1.first_name = "Sandra"
c1.save
c2.first_name = "Michael"
c2.save # Raises an ActiveRecord::StaleObjectError
然后,您有责任通过捕获异常并回滚、合并或以其他方式应用解决冲突所需的业务逻辑来处理冲突。
可以通过设置 ActiveRecord::Base.lock_optimistically = false 来关闭此行为。
要覆盖 lock_version 列的名称,ActiveRecord::Base 提供了一个名为 locking_column 的类属性
class Customer < ApplicationRecord
self.locking_column = :lock_customer_column
end
11.2. 悲观锁
悲观锁使用底层数据库提供的锁定机制。在构建关系时使用 lock 会在选定的行上获取排他锁。使用 lock 的关系通常封装在事务中以防止死锁条件。
例如
Book.transaction do
book = Book.lock.first
book.title = "Algorithms, second edition"
book.save!
end
上述会话为 MySQL 后端生成以下 SQL
SQL (0.2ms) BEGIN
Book Load (0.3ms) SELECT * FROM books LIMIT 1 FOR UPDATE
Book Update (0.4ms) UPDATE books SET updated_at = '2009-02-07 18:05:56', title = 'Algorithms, second edition' WHERE id = 1
SQL (0.8ms) COMMIT
您还可以向 lock 方法传递原始 SQL,以允许不同类型的锁。例如,MySQL 有一个名为 LOCK IN SHARE MODE 的表达式,您可以在其中锁定记录但仍允许其他查询读取它。要指定此表达式,只需将其作为锁选项传入即可
Book.transaction do
book = Book.lock("LOCK IN SHARE MODE").find(1)
book.increment!(:views)
end
请注意,您的数据库必须支持您传递给 lock 方法的原始 SQL。
如果您已经拥有模型实例,则可以使用以下代码启动事务并一次性获取锁
book = Book.first
book.with_lock do
# This block is called within a transaction,
# book is already locked.
book.increment!(:views)
end
12. 连接表
Active Record 提供了两种查找方法,用于在生成的 SQL 中指定 JOIN 子句:joins 和 left_outer_joins。joins 用于 INNER JOIN 或自定义查询,而 left_outer_joins 用于使用 LEFT OUTER JOIN 的查询。
12.1. joins
有多种方法可以使用 joins 方法。
12.1.1. 使用字符串 SQL 片段
您可以直接向 joins 提供指定 JOIN 子句的原始 SQL
Author.joins("INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE")
这将导致以下 SQL
SELECT authors.* FROM authors INNER JOIN books ON books.author_id = authors.id AND books.out_of_print = FALSE
12.1.2. 使用命名关联的数组/哈希
Active Record 允许您使用模型上定义的关联名称作为快捷方式,以便在使用 joins 方法时为这些关联指定 JOIN 子句。
以下所有内容都将使用 INNER JOIN 生成预期的连接查询
12.1.2.1. 连接单个关联
Book.joins(:reviews)
这将产生
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
或者,用英语来说:“返回所有有评论的书籍的 Book 对象”。请注意,如果一本书有多个评论,您将看到重复的书籍。如果您想要唯一的书籍,可以使用 Book.joins(:reviews).distinct。
12.1.3. 连接多个关联
Book.joins(:author, :reviews)
这将产生
SELECT books.* FROM books
INNER JOIN authors ON authors.id = books.author_id
INNER JOIN reviews ON reviews.book_id = books.id
或者,用英语来说:“返回所有有作者和至少一个评论的书籍”。再次注意,有多条评论的书籍将多次出现。
12.1.3.1. 连接嵌套关联(单层)
Book.joins(reviews: :customer)
这将产生
SELECT books.* FROM books
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
或者,用英语来说:“返回所有有客户评论的书籍。”
12.1.3.2. 连接嵌套关联(多层)
Author.joins(books: [{ reviews: { customer: :orders } }, :supplier])
这将产生
SELECT authors.* FROM authors
INNER JOIN books ON books.author_id = authors.id
INNER JOIN reviews ON reviews.book_id = books.id
INNER JOIN customers ON customers.id = reviews.customer_id
INNER JOIN orders ON orders.customer_id = customers.id
INNER JOIN suppliers ON suppliers.id = books.supplier_id
或者,用英语来说:“返回所有有评论书籍**并**已由客户订购的作者,以及这些书籍的供应商。”
12.1.4. 指定连接表的条件
您可以使用常规的 数组 和 字符串 条件来指定连接表的条件。哈希条件 提供了一种特殊的语法来指定连接表的条件
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where("orders.created_at" => time_range).distinct
这将查找所有在昨天有订单的客户,使用 BETWEEN SQL 表达式比较 created_at。
另一种更简洁的语法是嵌套哈希条件
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).where(orders: { created_at: time_range }).distinct
对于更高级的条件或重用现有命名作用域,可以使用 merge。首先,让我们向 Order 模型添加一个新的命名作用域
class Order < ApplicationRecord
belongs_to :customer
scope :created_in_time_range, ->(time_range) {
where(created_at: time_range)
}
end
现在我们可以使用 merge 来合并 created_in_time_range 作用域
time_range = (Time.now.midnight - 1.day)..Time.now.midnight
Customer.joins(:orders).merge(Order.created_in_time_range(time_range)).distinct
这将查找所有昨天创建订单的客户,再次使用 BETWEEN SQL 表达式。
12.2. left_outer_joins
如果您想选择一组记录,无论它们是否具有关联记录,您都可以使用 left_outer_joins 方法。
Customer.left_outer_joins(:reviews).distinct.select("customers.*, COUNT(reviews.*) AS reviews_count").group("customers.id")
这将产生
SELECT DISTINCT customers.*, COUNT(reviews.*) AS reviews_count FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id GROUP BY customers.id
这意味着:“返回所有客户及其评论数量,无论他们是否有任何评论”。
12.3. where.associated 和 where.missing
associated 和 missing 查询方法允许您根据关联的存在或缺失来选择一组记录。
使用 where.associated
Customer.where.associated(:reviews)
产生
SELECT customers.* FROM customers
INNER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NOT NULL
这意味着“返回所有至少做过一次评论的客户”。
使用 where.missing
Customer.where.missing(:reviews)
产生
SELECT customers.* FROM customers
LEFT OUTER JOIN reviews ON reviews.customer_id = customers.id
WHERE reviews.id IS NULL
这意味着“返回所有未做任何评论的客户”。
13. 预加载关联
预加载是一种机制,用于使用尽可能少的查询加载 Model.find 返回的对象的关联记录。
13.1. N + 1 查询问题
考虑以下代码,它查找 10 本书并打印其作者的 last_name
books = Book.limit(10)
books.each do |book|
puts book.author.last_name
end
这段代码乍一看没问题。但问题在于执行的总查询数量。上述代码总共执行 1(查找 10 本书)+ 10(每本书加载作者一个)= **11** 个查询。
13.1.1. N + 1 查询问题的解决方案
Active Record 允许您提前指定将要加载的所有关联。
这些方法是
13.2. includes
使用 includes,Active Record 确保使用尽可能少的查询加载所有指定的关联。
回顾上述使用 includes 方法的案例,我们可以重写 Book.limit(10) 以预加载作者
books = Book.includes(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
上述代码将只执行**2**个查询,而不是原始案例中的**11**个查询
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.id IN (1,2,3,4,5,6,7,8,9,10)
13.2.1. 预加载多个关联
Active Record 允许您使用 includes 方法中的数组、哈希或嵌套的数组/哈希哈希,通过单个 Model.find 调用预加载任意数量的关联。
13.2.1.1. 多个关联的数组
Customer.includes(:orders, :reviews)
这会加载所有客户以及每个客户的关联订单和评论。
13.2.1.2. 嵌套关联哈希
Customer.includes(orders: { books: [:supplier, :author] }).find(1)
这将查找 ID 为 1 的客户,并预加载其所有关联订单、所有订单的书籍以及每本书的作者和供应商。
13.2.2. 指定预加载关联的条件
尽管 Active Record 允许您像 joins 一样指定预加载关联的条件,但建议的方法是使用 joins。
但是,如果您必须这样做,您可以像通常那样使用 where。
Author.includes(:books).where(books: { out_of_print: true })
这将生成一个包含 LEFT OUTER JOIN 的查询,而 joins 方法将生成一个使用 INNER JOIN 函数的查询。
SELECT authors.id AS t0_r0, ... books.updated_at AS t1_r5 FROM authors LEFT OUTER JOIN books ON books.author_id = authors.id WHERE (books.out_of_print = 1)
如果没有 where 条件,这将生成正常的两组查询。
像这样使用 where 只在您传入哈希时有效。对于 SQL 片段,您需要使用 references 来强制连接表
Author.includes(:books).where("books.out_of_print = true").references(:books)
如果在这个 includes 查询中,任何作者都没有书籍,所有作者仍然会被加载。通过使用 joins (INNER JOIN),连接条件**必须**匹配,否则不会返回任何记录。
如果关联作为连接的一部分被预加载,则自定义 select 子句中的任何字段都不会出现在加载的模型上。这是因为它们应该出现在父记录还是子记录上是不明确的。
13.3. preload
使用 preload,Active Record 会为每个指定的关联使用一次查询加载。
回顾 N + 1 查询问题,我们可以重写 Book.limit(10) 以预加载作者
books = Book.preload(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
上述代码将只执行**2**个查询,而不是原始案例中的**11**个查询
SELECT books.* FROM books LIMIT 10
SELECT authors.* FROM authors
WHERE authors.id IN (1,2,3,4,5,6,7,8,9,10)
preload 方法以与 includes 方法相同的方式使用数组、哈希或嵌套的数组/哈希哈希,通过单个 Model.find 调用加载任意数量的关联。但是,与 includes 方法不同,无法为预加载的关联指定条件。
13.4. eager_load
使用 eager_load,Active Record 使用 LEFT OUTER JOIN 加载所有指定的关联。
回顾使用 eager_load 方法发生 N + 1 的情况,我们可以重写 Book.limit(10) 以预加载作者
books = Book.eager_load(:author).limit(10)
books.each do |book|
puts book.author.last_name
end
上述代码将只执行**1**个查询,而不是原始案例中的**11**个查询
SELECT "books"."id" AS t0_r0, "books"."title" AS t0_r1, ... FROM "books"
LEFT OUTER JOIN "authors" ON "authors"."id" = "books"."author_id"
LIMIT 10
eager_load 方法以与 includes 方法相同的方式使用数组、哈希或嵌套的数组/哈希哈希,通过单个 Model.find 调用加载任意数量的关联。此外,与 includes 方法一样,您可以为预加载的关联指定条件。
13.5. strict_loading
预加载可以防止 N + 1 查询,但您可能仍然会惰性加载一些关联。为确保没有关联被惰性加载,您可以启用 strict_loading。
通过在关系上启用严格加载模式,如果记录尝试惰性加载任何关联,将引发 ActiveRecord::StrictLoadingViolationError
user = User.strict_loading.first
user.address.city # raises an ActiveRecord::StrictLoadingViolationError
user.comments.to_a # raises an ActiveRecord::StrictLoadingViolationError
要为所有关系启用,请将 config.active_record.strict_loading_by_default 标志更改为 true。
要将违规发送到日志器,请将 config.active_record.action_on_strict_loading_violation 更改为 :log。
13.6. strict_loading!
我们还可以通过调用 strict_loading! 在记录本身上启用严格加载
user = User.first
user.strict_loading!
user.address.city # raises an ActiveRecord::StrictLoadingViolationError
user.comments.to_a # raises an ActiveRecord::StrictLoadingViolationError
strict_loading! 也接受 :mode 参数。将其设置为 :n_plus_one_only 将仅在导致 N + 1 查询的关联被惰性加载时引发错误
user.strict_loading!(mode: :n_plus_one_only)
user.address.city # => "Tatooine"
user.comments.to_a # => [#<Comment:0x00...]
user.comments.first.likes.to_a # raises an ActiveRecord::StrictLoadingViolationError
13.7. 关联上的 strict_loading 选项
我们还可以通过提供 strict_loading 选项为单个关联启用严格加载
class Author < ApplicationRecord
has_many :books, strict_loading: true
end
14. 作用域
作用域允许您指定常用的查询,这些查询可以作为关联对象或模型上的方法调用来引用。通过这些作用域,您可以使用之前涵盖的所有方法,例如 where、joins 和 includes。所有作用域主体都应返回 ActiveRecord::Relation 或 nil,以允许在其上调用更多方法(例如其他作用域)。
要定义一个简单的作用域,我们在类内部使用 scope 方法,传入我们希望在此作用域被调用时运行的查询
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
end
要调用此 out_of_print 作用域,我们可以在类上调用它
irb> Book.out_of_print
=> #<ActiveRecord::Relation> # all out of print books
或在由 Book 对象组成的关联上
irb> author = Author.first
irb> author.books.out_of_print
=> #<ActiveRecord::Relation> # all out of print books by `author`
作用域也可以在作用域内链式调用
class Book < ApplicationRecord
scope :out_of_print, -> { where(out_of_print: true) }
scope :out_of_print_and_expensive, -> { out_of_print.where("price > 500") }
end
14.1. 传入参数
您的作用域可以接受参数
class Book < ApplicationRecord
scope :costs_more_than, ->(amount) { where("price > ?", amount) }
end
像调用类方法一样调用作用域
irb> Book.costs_more_than(100.10)
然而,这只是重复了类方法将为您提供的功能。
class Book < ApplicationRecord
def self.costs_more_than(amount)
where("price > ?", amount)
end
end
这些方法仍然可以在关联对象上访问
irb> author.books.costs_more_than(100.10)
14.2. 使用条件
您的作用域可以使用条件
class Order < ApplicationRecord
scope :created_before, ->(time) { where(created_at: ...time) if time.present? }
end
像其他示例一样,这将类似于类方法。
class Order < ApplicationRecord
def self.created_before(time)
where(created_at: ...time) if time.present?
end
end
然而,有一个重要的注意事项:作用域将始终返回一个 ActiveRecord::Relation 对象,即使条件评估为 false,而类方法将返回 nil。当链式调用带有条件的类方法时,如果任何条件返回 false,这可能会导致 NoMethodError。
14.3. 应用默认作用域
如果希望将作用域应用于模型的所有查询,我们可以使用模型本身中的 default_scope 方法。
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
当在此模型上执行查询时,SQL 查询现在将类似于
SELECT * FROM books WHERE (out_of_print = false)
如果您需要使用默认作用域执行更复杂的操作,也可以将其定义为类方法
class Book < ApplicationRecord
def self.default_scope
# Should return an ActiveRecord::Relation.
end
end
当作用域参数以 Hash 形式给出时,default_scope 在创建/构建记录时也会应用。在更新记录时则不应用。例如
class Book < ApplicationRecord
default_scope { where(out_of_print: false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: false>
irb> Book.unscoped.new
=> #<Book id: nil, out_of_print: nil>
请注意,当以 Array 格式给出时,default_scope 查询参数无法转换为 Hash 以进行默认属性分配。例如
class Book < ApplicationRecord
default_scope { where("out_of_print = ?", false) }
end
irb> Book.new
=> #<Book id: nil, out_of_print: nil>
14.4. 作用域的合并
就像 where 子句一样,作用域使用 AND 条件合并。
class Book < ApplicationRecord
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
scope :recent, -> { where(year_published: 50.years.ago.year..) }
scope :old, -> { where(year_published: ...50.years.ago.year) }
end
irb> Book.out_of_print.old
SELECT books.* FROM books WHERE books.out_of_print = 'true' AND books.year_published < 1969
我们可以混合和匹配 scope 和 where 条件,最终的 SQL 将所有条件与 AND 连接起来。
irb> Book.in_print.where(price: ...100)
SELECT books.* FROM books WHERE books.out_of_print = 'false' AND books.price < 100
如果我们确实希望最后一个 where 子句获胜,则可以使用 merge。
irb> Book.in_print.merge(Book.out_of_print)
SELECT books.* FROM books WHERE books.out_of_print = true
一个重要的注意事项是,default_scope 将在 scope 和 where 条件中预置。
class Book < ApplicationRecord
default_scope { where(year_published: 50.years.ago.year..) }
scope :in_print, -> { where(out_of_print: false) }
scope :out_of_print, -> { where(out_of_print: true) }
end
irb> Book.all
SELECT books.* FROM books WHERE (year_published >= 1969)
irb> Book.in_print
SELECT books.* FROM books WHERE (year_published >= 1969) AND books.out_of_print = false
irb> Book.where('price > 50')
SELECT books.* FROM books WHERE (year_published >= 1969) AND (price > 50)
如上所示,default_scope 合并到 scope 和 where 条件中。
14.5. 移除所有作用域
如果我们需要出于任何原因删除作用域,可以使用 unscoped 方法。当模型中指定了 default_scope 并且不应应用于此特定查询时,此方法特别有用。
Book.unscoped.load
此方法删除所有作用域,并将对表执行正常查询。
irb> Book.unscoped.all
SELECT books.* FROM books
irb> Book.where(out_of_print: true).unscoped.all
SELECT books.* FROM books
unscoped 也可以接受一个块
irb> Book.unscoped { Book.out_of_print }
SELECT books.* FROM books WHERE books.out_of_print = true
15. 动态查找器
对于您在表中定义的每个字段(也称为属性),Active Record 都提供了一个查找器方法。例如,如果您的 Customer 模型上有一个名为 first_name 的字段,您将免费获得 Active Record 提供的实例方法 find_by_first_name。如果 Customer 模型上还有一个 locked 字段,您还将获得 find_by_locked 方法。
您可以在动态查找器的末尾指定感叹号(!),以使其在不返回任何记录时引发 ActiveRecord::RecordNotFound 错误,例如 Customer.find_by_first_name!("Ryan")
如果您想同时按 first_name 和 orders_count 查找,您可以通过简单地在字段之间键入“and”来链式调用这些查找器。例如,Customer.find_by_first_name_and_orders_count("Ryan", 5)。
16. 枚举
枚举允许您为属性定义一个值数组,并按名称引用它们。数据库中存储的实际值是一个已映射到其中一个值的整数。
声明枚举将
- 创建可用于查找具有或不具有枚举值之一的所有对象的范围
- 创建可用于确定对象是否具有枚举特定值的实例方法
- 创建可用于更改对象枚举值的实例方法
适用于枚举的所有可能值。
例如,给定此 enum 声明
class Order < ApplicationRecord
enum :status, [:shipped, :being_packaged, :complete, :cancelled]
end
这些 作用域 会自动创建,可用于查找具有或不具有 status 特定值的所有对象
irb> Order.shipped
=> #<ActiveRecord::Relation> # all orders with status == :shipped
irb> Order.not_shipped
=> #<ActiveRecord::Relation> # all orders with status != :shipped
这些实例方法会自动创建,并查询模型是否具有 status 枚举的该值
irb> order = Order.shipped.first
irb> order.shipped?
=> true
irb> order.complete?
=> false
这些实例方法会自动创建,它们首先将 status 的值更新为指定值,然后查询状态是否已成功设置为该值
irb> order = Order.first
irb> order.shipped!
UPDATE "orders" SET "status" = ?, "updated_at" = ? WHERE "orders"."id" = ? [["status", 0], ["updated_at", "2019-01-24 07:13:08.524320"], ["id", 1]]
=> true
有关枚举的完整文档可以在 此处 找到。
17. 理解方法链
Active Record 模式实现了 方法链,这允许我们以简单直接的方式将多个 Active Record 方法一起使用。
当上一个方法调用返回 ActiveRecord::Relation 时,例如 all、where 和 joins,您可以在语句中链式调用方法。返回单个对象的方法(参见 检索单个对象部分)必须位于语句的末尾。
下面有一些例子。本指南不会涵盖所有可能性,仅作为例子介绍几个。当调用 Active Record 方法时,查询不会立即生成并发送到数据库。查询仅在实际需要数据时才发送。因此,下面的每个示例都生成一个查询。
17.1. 从多个表检索过滤数据
Customer
.select("customers.id, customers.last_name, reviews.body")
.joins(:reviews)
.where("reviews.created_at > ?", 1.week.ago)
结果应该是这样的
SELECT customers.id, customers.last_name, reviews.body
FROM customers
INNER JOIN reviews
ON reviews.customer_id = customers.id
WHERE (reviews.created_at > '2019-01-08')
17.2. 从多个表检索特定数据
Book
.select("books.id, books.title, authors.first_name")
.joins(:author)
.find_by(title: "Abstraction and Specification in Program Development")
上述内容应该生成
SELECT books.id, books.title, authors.first_name
FROM books
INNER JOIN authors
ON authors.id = books.author_id
WHERE books.title = $1 [["title", "Abstraction and Specification in Program Development"]]
LIMIT 1
请注意,如果查询匹配多条记录,find_by 将只获取第一条并忽略其他记录(参见上面的 LIMIT 1 语句)。
18. 查找或构建新对象
通常需要查找记录,如果不存在则创建它。您可以使用 find_or_create_by 和 find_or_create_by! 方法来完成此操作。
18.1. find_or_create_by
find_or_create_by 方法检查是否存在具有指定属性的记录。如果不存在,则调用 create。让我们看一个例子。
假设您想查找名为“Andy”的客户,如果不存在,则创建一个。您可以通过运行以下命令来完成此操作
irb> Customer.find_or_create_by(first_name: 'Andy')
=> #<Customer id: 5, first_name: "Andy", last_name: nil, title: nil, visits: 0, orders_count: nil, lock_version: 0, created_at: "2019-01-17 07:06:45", updated_at: "2019-01-17 07:06:45">
此方法生成的 SQL 如下所示
SELECT * FROM customers WHERE (customers.first_name = 'Andy') LIMIT 1
BEGIN
INSERT INTO customers (created_at, first_name, locked, orders_count, updated_at) VALUES ('2011-08-30 05:22:57', 'Andy', 1, NULL, '2011-08-30 05:22:57')
COMMIT
find_or_create_by 返回已存在的记录或新记录。在我们的例子中,我们没有名为 Andy 的客户,因此创建并返回了该记录。
新记录可能不会保存到数据库;这取决于验证是否通过(就像 create 一样)。
假设我们想在创建新记录时将 'locked' 属性设置为 false,但我们不想将其包含在查询中。因此,我们想查找名为“Andy”的客户,如果该客户不存在,则创建一个名为“Andy”且未锁定的客户。
我们可以通过两种方式实现这一点。第一种是使用 create_with
Customer.create_with(locked: false).find_or_create_by(first_name: "Andy")
第二种方法是使用块
Customer.find_or_create_by(first_name: "Andy") do |c|
c.locked = false
end
该块只会在创建客户时执行。第二次运行此代码时,该块将被忽略。
18.2. find_or_create_by!
您还可以使用 find_or_create_by! 来在新记录无效时引发异常。本指南不涵盖验证,但让我们假设您暂时将
validates :orders_count, presence: true
添加到您的 Customer 模型。如果您尝试创建一个新的 Customer 而不传入 orders_count,则记录将无效并引发异常
irb> Customer.find_or_create_by!(first_name: 'Andy')
ActiveRecord::RecordInvalid: Validation failed: Orders count can't be blank
18.3. find_or_initialize_by
find_or_initialize_by 方法的行为与 find_or_create_by 完全相同,但它将调用 new 而不是 create。这意味着将在内存中创建一个新的模型实例,但不会保存到数据库中。继续 find_or_create_by 示例,我们现在需要名为“Nina”的客户
irb> nina = Customer.find_or_initialize_by(first_name: 'Nina')
=> #<Customer id: nil, first_name: "Nina", orders_count: 0, locked: true, created_at: "2011-08-30 06:09:27", updated_at: "2011-08-30 06:09:27">
irb> nina.persisted?
=> false
irb> nina.new_record?
=> true
由于对象尚未存储在数据库中,因此生成的 SQL 如下所示
SELECT * FROM customers WHERE (customers.first_name = 'Nina') LIMIT 1
当您想将其保存到数据库时,只需调用 save
irb> nina.save
=> true
19. 通过 SQL 查找
如果您想使用自己的 SQL 在表中查找记录,可以使用 find_by_sql。find_by_sql 方法将返回一个对象数组,即使底层查询只返回一条记录。例如,您可以运行此查询
irb> Customer.find_by_sql("SELECT * FROM customers INNER JOIN orders ON customers.id = orders.customer_id ORDER BY customers.created_at desc")
=> [#<Customer id: 1, first_name: "Lucas" ...>, #<Customer id: 2, first_name: "Jan" ...>, ...]
find_by_sql 为您提供了一种简单的方法,可以对数据库进行自定义调用并检索实例化对象。
19.1. select_all
find_by_sql 有一个近亲,叫做 lease_connection.select_all。select_all 将使用自定义 SQL 从数据库中检索对象,就像 find_by_sql 一样,但不会实例化它们。此方法将返回 ActiveRecord::Result 类的实例,对此对象调用 to_a 将返回一个哈希数组,其中每个哈希表示一条记录。
irb> Customer.lease_connection.select_all("SELECT first_name, created_at FROM customers WHERE id = '1'").to_a
=> [{"first_name"=>"Rafael", "created_at"=>"2012-11-10 23:23:45.281189"}, {"first_name"=>"Eileen", "created_at"=>"2013-12-09 11:22:35.221282"}]
19.2. pluck
pluck 可用于从当前关系中命名的列中选取值。它接受列名列表作为参数,并返回指定列的值数组,其中包含相应的数据类型。
irb> Book.where(out_of_print: true).pluck(:id)
SELECT id FROM books WHERE out_of_print = true
=> [1, 2, 3]
irb> Order.distinct.pluck(:status)
SELECT DISTINCT status FROM orders
=> ["shipped", "being_packed", "cancelled"]
irb> Customer.pluck(:id, :first_name)
SELECT customers.id, customers.first_name FROM customers
=> [[1, "David"], [2, "Fran"], [3, "Jose"]]
pluck 使替换以下代码成为可能
Customer.select(:id).map { |c| c.id }
# or
Customer.select(:id).map(&:id)
# or
Customer.select(:id, :first_name).map { |c| [c.id, c.first_name] }
用
Customer.pluck(:id)
# or
Customer.pluck(:id, :first_name)
与 select 不同,pluck 直接将数据库结果转换为 Ruby Array,而无需构建 ActiveRecord 对象。这对于大型或频繁运行的查询可能意味着更好的性能。但是,任何模型方法覆盖都将不可用。例如
class Customer < ApplicationRecord
def name
"I am #{first_name}"
end
end
irb> Customer.select(:first_name).map &:name
=> ["I am David", "I am Jeremy", "I am Jose"]
irb> Customer.pluck(:first_name)
=> ["David", "Jeremy", "Jose"]
您不仅限于查询单个表中的字段,还可以查询多个表。
irb> Order.joins(:customer, :books).pluck("orders.created_at, customers.email, books.title")
此外,与 select 和其他 Relation 作用域不同,pluck 会立即触发查询,因此不能与任何进一步的作用域链式调用,尽管它可以与先前构建的作用域一起使用
irb> Customer.pluck(:first_name).limit(1)
NoMethodError: undefined method `limit' for #<Array:0x007ff34d3ad6d8>
irb> Customer.limit(1).pluck(:first_name)
=> ["David"]
您还应该知道,如果关系对象包含 includes 值,即使查询不需要预加载,使用 pluck 也会触发预加载。例如
irb> assoc = Customer.includes(:reviews)
irb> assoc.pluck(:id)
SELECT "customers"."id" FROM "customers" LEFT OUTER JOIN "reviews" ON "reviews"."id" = "customers"."review_id"
避免这种情况的一种方法是 unscope 掉 includes
irb> assoc.unscope(:includes).pluck(:id)
19.3. pick
pick 可用于从当前关系中命名的列中选取值。它接受列名列表作为参数,并返回指定列值的第一个行以及相应的数据类型。pick 是 relation.limit(1).pluck(*column_names).first 的简写,主要在您已经拥有一个限制为一行的关系时有用。
pick 使替换以下代码成为可能
Customer.where(id: 1).pluck(:id).first
用
Customer.where(id: 1).pick(:id)
19.4. ids
ids 可用于使用表的主键获取关系的所有 ID。
irb> Customer.ids
SELECT id FROM customers
class Customer < ApplicationRecord
self.primary_key = "customer_id"
end
irb> Customer.ids
SELECT customer_id FROM customers
20. 对象的存在
如果您只是想检查对象的存在性,有一个名为 exists? 的方法。此方法将使用与 find 相同的查询来查询数据库,但它不会返回对象或对象集合,而是返回 true 或 false。
Customer.exists?(1)
exists? 方法也接受多个值,但问题是如果其中任何一个记录存在,它将返回 true。
Customer.exists?(id: [1, 2, 3])
# or
Customer.exists?(first_name: ["Jane", "Sergei"])
甚至可以在模型或关系上不带任何参数使用 exists?。
Customer.where(first_name: "Ryan").exists?
如果存在至少一个 first_name 为 'Ryan' 的客户,则上述代码返回 true,否则返回 false。
Customer.exists?
如果 customers 表为空,则上述返回 false,否则返回 true。
您还可以使用 any? 和 many? 来检查模型或关系是否存在。many? 将使用 SQL count 来确定项目是否存在。
# via a model
Order.any?
# SELECT 1 FROM orders LIMIT 1
Order.many?
# SELECT COUNT(*) FROM (SELECT 1 FROM orders LIMIT 2)
# via a named scope
Order.shipped.any?
# SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 1
Order.shipped.many?
# SELECT COUNT(*) FROM (SELECT 1 FROM orders WHERE orders.status = 0 LIMIT 2)
# via a relation
Book.where(out_of_print: true).any?
Book.where(out_of_print: true).many?
# via an association
Customer.first.orders.any?
Customer.first.orders.many?
21. 计算
本节以 count 作为序言中的示例方法,但所述选项适用于所有小节。
所有计算方法都直接作用于模型
irb> Customer.count
SELECT COUNT(*) FROM customers
或作用于关系
irb> Customer.where(first_name: 'Ryan').count
SELECT COUNT(*) FROM customers WHERE (first_name = 'Ryan')
您还可以使用关系上的各种查找方法来执行复杂计算
irb> Customer.includes("orders").where(first_name: 'Ryan', orders: { status: 'shipped' }).count
这将执行
SELECT COUNT(DISTINCT customers.id) FROM customers
LEFT OUTER JOIN orders ON orders.customer_id = customers.id
WHERE (customers.first_name = 'Ryan' AND orders.status = 0)
假设 Order 具有 enum status: [ :shipped, :being_packed, :cancelled ]。
21.1. count
如果您想查看模型表中有多少条记录,可以调用 Customer.count,它将返回该数字。如果您想更具体地查找数据库中存在标题的所有客户,可以使用 Customer.count(:title)。
有关选项,请参阅父部分 计算。
21.2. average
如果您想查看表中某个数字的平均值,可以在与该表相关的类上调用 average 方法。此方法调用将如下所示
Order.average("subtotal")
这将返回一个数字(可能是浮点数,例如 3.14159265),表示字段中的平均值。
有关选项,请参阅父部分 计算。
21.3. minimum
如果您想在表中查找字段的最小值,可以在与该表相关的类上调用 minimum 方法。此方法调用将如下所示
Order.minimum("subtotal")
有关选项,请参阅父部分 计算。
21.4. maximum
如果您想在表中查找字段的最大值,可以在与该表相关的类上调用 maximum 方法。此方法调用将如下所示
Order.maximum("subtotal")
有关选项,请参阅父部分 计算。
21.5. sum
如果您想查找表中所有记录的字段总和,可以在与该表相关的类上调用 sum 方法。此方法调用将如下所示
Order.sum("subtotal")
有关选项,请参阅父部分 计算。
22. 运行 EXPLAIN
您可以对关系运行 explain。EXPLAIN 输出因每个数据库而异。
例如,运行
Customer.where(id: 1).joins(:orders).explain
可能会为 MySQL 和 MariaDB 生成如下结果
EXPLAIN SELECT `customers`.* FROM `customers` INNER JOIN `orders` ON `orders`.`customer_id` = `customers`.`id` WHERE `customers`.`id` = 1
+----+-------------+------------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+------------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+------------+-------+---------------+
+---------+---------+-------+------+-------------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------------+
| PRIMARY | 4 | const | 1 | |
| NULL | NULL | NULL | 1 | Using where |
+---------+---------+-------+------+-------------+
2 rows in set (0.00 sec)
Active Record 执行的漂亮打印功能模拟了相应数据库 shell 的输出。因此,使用 PostgreSQL 适配器运行相同的查询将生成
EXPLAIN SELECT "customers".* FROM "customers" INNER JOIN "orders" ON "orders"."customer_id" = "customers"."id" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=4.33..20.85 rows=4 width=164)
-> Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
-> Bitmap Heap Scan on orders (cost=4.18..12.64 rows=4 width=8)
Recheck Cond: (customer_id = '1'::bigint)
-> Bitmap Index Scan on index_orders_on_customer_id (cost=0.00..4.18 rows=4 width=0)
Index Cond: (customer_id = '1'::bigint)
(7 rows)
预加载可能会在后台触发多个查询,并且某些查询可能需要前一个查询的结果。因此,explain 实际上会执行查询,然后请求查询计划。例如,运行
Customer.where(id: 1).includes(:orders).explain
可能会为 MySQL 和 MariaDB 生成如下结果
EXPLAIN SELECT `customers`.* FROM `customers` WHERE `customers`.`id` = 1
+----+-------------+-----------+-------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+-----------+-------+---------------+
| 1 | SIMPLE | customers | const | PRIMARY |
+----+-------------+-----------+-------+---------------+
+---------+---------+-------+------+-------+
| key | key_len | ref | rows | Extra |
+---------+---------+-------+------+-------+
| PRIMARY | 4 | const | 1 | |
+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
EXPLAIN SELECT `orders`.* FROM `orders` WHERE `orders`.`customer_id` IN (1)
+----+-------------+--------+------+---------------+
| id | select_type | table | type | possible_keys |
+----+-------------+--------+------+---------------+
| 1 | SIMPLE | orders | ALL | NULL |
+----+-------------+--------+------+---------------+
+------+---------+------+------+-------------+
| key | key_len | ref | rows | Extra |
+------+---------+------+------+-------------+
| NULL | NULL | NULL | 1 | Using where |
+------+---------+------+------+-------------+
1 row in set (0.00 sec)
并且可能会为 PostgreSQL 生成如下结果
Customer Load (0.3ms) SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
Order Load (0.3ms) SELECT "orders".* FROM "orders" WHERE "orders"."customer_id" = $1 [["customer_id", 1]]
=> EXPLAIN SELECT "customers".* FROM "customers" WHERE "customers"."id" = $1 [["id", 1]]
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using customers_pkey on customers (cost=0.15..8.17 rows=1 width=164)
Index Cond: (id = '1'::bigint)
(2 rows)
22.1. 解释选项
对于支持它们的数据库和适配器(目前是 PostgreSQL、MySQL 和 MariaDB),可以传递选项以提供更深入的分析。
使用 PostgreSQL,以下内容
Customer.where(id: 1).joins(:orders).explain(:analyze, :verbose)
产生
EXPLAIN (ANALYZE, VERBOSE) SELECT "shop_accounts".* FROM "shop_accounts" INNER JOIN "customers" ON "customers"."id" = "shop_accounts"."customer_id" WHERE "shop_accounts"."id" = $1 [["id", 1]]
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Nested Loop (cost=0.30..16.37 rows=1 width=24) (actual time=0.003..0.004 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Inner Unique: true
-> Index Scan using shop_accounts_pkey on public.shop_accounts (cost=0.15..8.17 rows=1 width=24) (actual time=0.003..0.003 rows=0 loops=1)
Output: shop_accounts.id, shop_accounts.customer_id, shop_accounts.customer_carrier_id
Index Cond: (shop_accounts.id = '1'::bigint)
-> Index Only Scan using customers_pkey on public.customers (cost=0.15..8.17 rows=1 width=8) (never executed)
Output: customers.id
Index Cond: (customers.id = shop_accounts.customer_id)
Heap Fetches: 0
Planning Time: 0.063 ms
Execution Time: 0.011 ms
(12 rows)
使用 MySQL 或 MariaDB,以下内容
Customer.where(id: 1).joins(:orders).explain(:analyze)
产生
ANALYZE SELECT `shop_accounts`.* FROM `shop_accounts` INNER JOIN `customers` ON `customers`.`id` = `shop_accounts`.`customer_id` WHERE `shop_accounts`.`id` = 1
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | r_rows | filtered | r_filtered | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | no matching row in const table |
+----+-------------+-------+------+---------------+------+---------+------+------+--------+----------+------------+--------------------------------+
1 row in set (0.00 sec)
22.2. 解释 EXPLAIN
解释 EXPLAIN 输出超出了本指南的范围。以下提示可能会有所帮助
SQLite3:EXPLAIN QUERY PLAN
MySQL:EXPLAIN 输出格式
MariaDB:EXPLAIN
PostgreSQL:使用 EXPLAIN